Diffusion-based accent modelling in speech synthesis
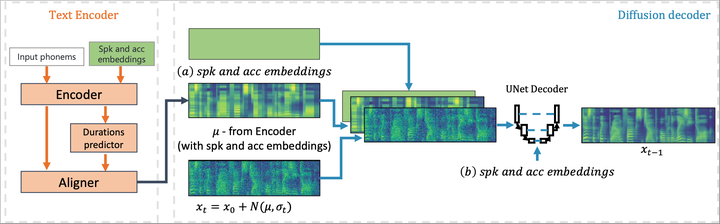 Architecture of the accented diffusion model
Architecture of the accented diffusion modelAbstract
In this work, we introduce a diffusion-based text-to-speech (TTS) system for accent modelling. TTS systems have become a natural part of our surroundings. Nevertheless, because of the complexity of accent modelling, recent state-of-the-art solutions mainly focus on the most common variants of each language. In this work, we propose to address this issue with a newly proposed diffusion generative model (DDGM). We first show how we can adapt DDGMs to the problem of accent modelling. We evaluate and compare this approach with a recent state-of-the-art solution, showing its superiority in modelling six different English accents. On top of our TTS system, we introduce a novel accent conversion method, where using the saliency map technique, we remove source accent-related features and replace them with the target ones through the diffusion process. We show that with this approach, we can perform accent conversion without a need for any additional speech information such as phonemes or text.
Georgi Tinchev
Scientist @ Amazon Alexa
My research interests include computer vision, robotics, and machine learning.